
How to Choose the Right Database for Your Serverless Application
Serverless promises to free teams from infrastructure worries, but picking the wrong database can hurt your performance, increase your costs, and affect developer velocity.
As with everything in software, the database choice comes with trade-offs, and understanding what are those are extremely important. Scaling characteristics, connection handling and concurrency, latency, consistency and transactional needs, operational overhead, and pricing model are all factors to consider.
This article unpacks those trade-offs, compares common patterns (serverless‑native databases, managed relational options, caches, and streaming stores), and offers practical rules of thumb so you can pick a database that fits your application rather than creating new operational headaches. By the end, you’ll have a concise checklist to make the decision faster and more confidently.
Why database choice matters more in serverless
In traditional servers, database connections are opened once and reused across thousands of requests. Application instances are long‑lived and predictable. Serverless flips that model: functions spin up, live for seconds or minutes, and vanish. Each invocation may be a fresh process with no previous state, no persistent connection, and no guarantee of locality to previous requests. That changes the calculus: connection limits, cold‑start penalties, and per‑operation pricing matter far more than they did in long‑running servers.
A database that works well behind a long‑lived app can cause connection storms, latency spikes, or runaway costs when used directly from a fleet of ephemeral functions. The goal is to match your workload’s requirements (throughput, latency, consistency, transactions) with a storage option whose trade‑offs align with serverless behavior.
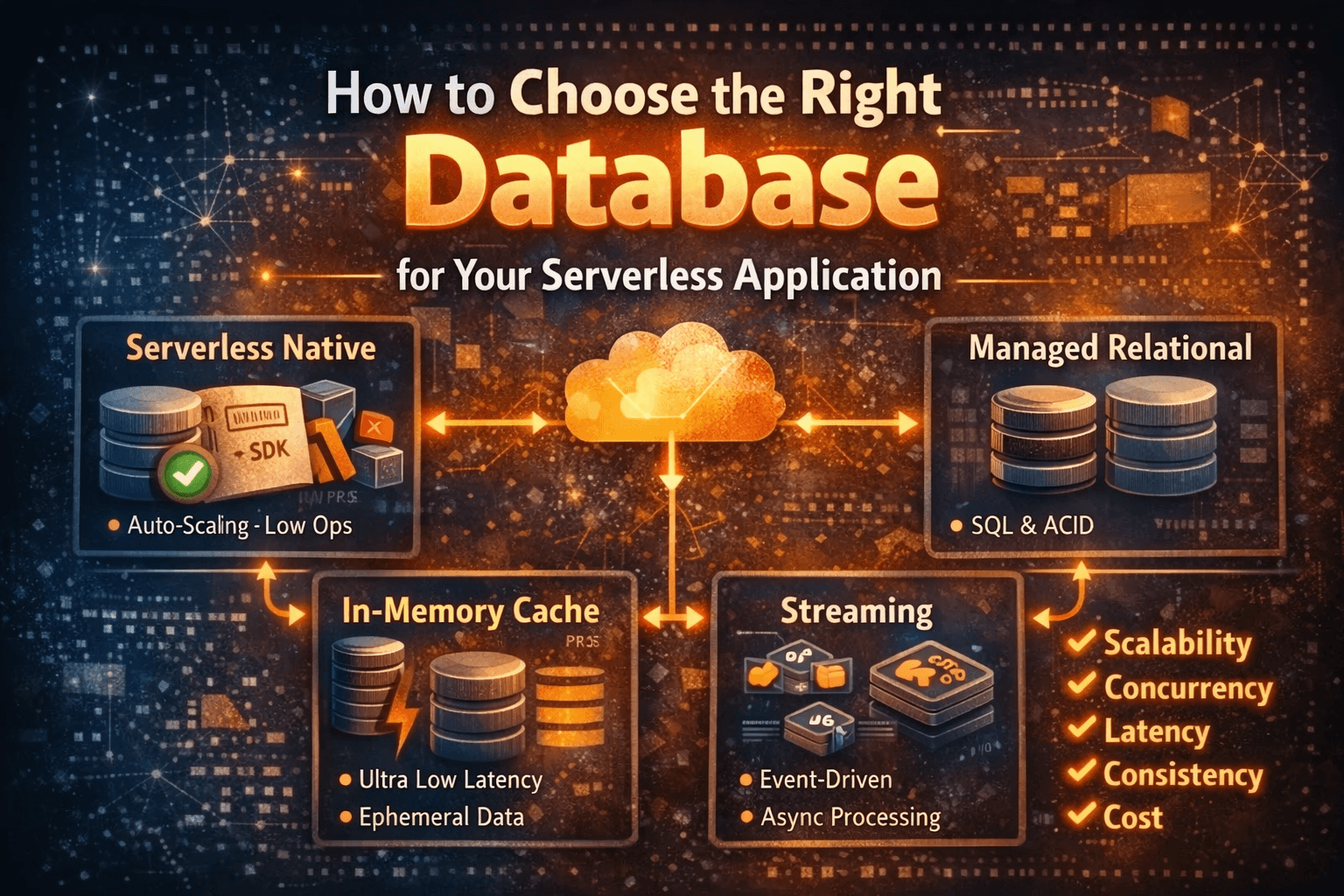
Key trade-offs to weigh
Scaling characteristics: Does the database scale horizontally without connection limits or shard coordination that conflicts with ephemeral clients?
Connection handling and concurrency: Can thousands of short‑lived connections be supported efficiently, or do you need a pooling/proxy layer?
Latency: Are single‑digit‑millisecond reads required, or can you accept higher, variable latency?
Consistency and transactions: Do you need strong ACID guarantees across multiple keys/tables, or is eventual consistency acceptable?
Operational overhead: How much maintenance, tuning, backups, and failover handling will your team manage?
Pricing model: Per‑operation, provisioned capacity, or storage‑centric billing—how do patterns of traffic (spiky vs steady) affect cost?
Common patterns and how they map to serverless
Serverless‑native databases (e.g., serverless NoSQL or fully serverless managed stores):
Pros: Auto‑scaling, connectionless or HTTP/SDK access, fine‑grained billing, low operational overhead.
Cons: Weaker transactional guarantees or complex modeling for relational data; can be expensive at very high sustained throughput.
When to use: Spiky workloads, simple access patterns, evented architectures, or when you want minimal ops.
Managed relational databases (serverless variants or provisioned RDS/Aurora/etc.):
Pros: Familiar SQL, strong transactions, complex queries.
Cons: Connection limits and scaling challenges; may require connection pooling (proxy, pooler, or Data API) and can incur cold‑start latency.
When to use: Applications that require ACID across multiple records or complex joins and cannot be re‑modeled easily.
Caches and in‑memory stores (Redis, Memcached, or managed variants):
Pros: Extremely low latency for hot reads, useful for rate limiting, sessions, and ephemeral state.
Cons: Not a durable primary store (unless using persistence features), additional operational cost, eventual consistency with origin store.
When to use: Read‑heavy, low‑latency needs, offloading hotspots from a primary datastore.
Streaming/append logs (Kafka, Kinesis, Pulsar, streaming databases):
Pros: Durable event delivery, great for event‑sourcing, async processing, and decoupling components.
Cons: Not a drop‑in replacement for arbitrary reads/transactions; requires different application patterns.
When to use: Event‑driven architectures, audit logs, long‑running workflows.
Practical rules of thumb
If your functions open many short‑lived DB connections, use a serverless‑friendly datastore or a connection proxy. Don’t rely on direct DB connections from unpooled functions.
For strong multi‑row/multi‑table transactions choose managed relational options—but consider a serverless (Data API) or pooled access pattern to avoid connection storms.
For spiky traffic with bursty reads, prefer serverless‑native stores and caches; they scale on demand and bill for usage.
If your app can tolerate eventual consistency, embracing key‑value or document models often reduces complexity and cost.
Use streaming stores for durable event capture and decoupling; combine with a materialized view or read store for low‑latency queries.
Measure cost at expected traffic patterns—serverless pricing can be higher for sustained, heavy throughput than for bursty, intermittent use.
Closing thoughts
Choosing a database for serverless shouldn’t be guesswork. Match your access patterns and operational constraints to the storage option whose trade‑offs you can live with, and use small experiments to validate latency, scaling, and cost under realistic load. This keeps serverless simple, where it should be—letting your team move faster without trading away reliability or spiraling costs.



